【背景】要将Hbase 从0.94.2(hadoop-1.0.4)升级到1.0.0(hadoop-2.5.2),目前采取的方案是重新搭建一套集群,将原有的Hbase数据导出(export)再导入(import)到新的集群上,期间遇到了很多问题,走了很多弯路,最后还是成功完成升级,特此记录一下,有类似需求的可以参考一下。
Hbase导入导出方法有很多(可参考cloudera介绍):
Export/Import CopyTable Snapshots BulkLoad (这是clouder推荐的:适合大数据量的导出导入) Cluster Replication Pig and HCatalog the Java API the Apache Thrift Proxy API the REST Proxy API Flume Spark Spark and Kafka a Custom MapReduce Job
由于本次升级涉及到跨版本问题,而且是跨越了两个版本:0.96,0.98,直接升级到了1.0.0,为防止Hbase因为版本升级带来的数据格式上的问题,首先尝试的是使用Export/Import方式。
基本步骤如下:
1.新集群的搭建Hadoop-2.5.2+Hbase-1.0.0
搭建新集群的时候还有些曲折:
(1)本来使用的是Hadoop-2.6.0+Hbase-1.0.0的组合,后来发现启动hbase的时候有些报错:
2015-04-21 21:56:24,679 FATAL [hadoopnn:16020.activeMasterManager] master.HMaster: Failed to become active master org.apache.hadoop.hbase.TableExistsException: hbase:namespace
担心步子大了扯着蛋,网上有说Hadoop-2.6.0+Hbase-1.0.0这两个版本不兼容(没继续查找原因),安全起见降低了hadoop版本,换成了现在的Hadoop-2.5.2+Hbase-1.0.0组合。
(2)mvn编译hadoop的时候有些慢,不同的子项目居然傻乎乎的下载两遍tomcat。。
2.从原Hbase-0.94.2的集群上导出Hbase表
假设导出的表为TestTable
(1)尝试导出到本地硬盘:
/home/hadoop/hbase/bin/hbase org.apache.hadoop.hbase.mapreduce.Driver export \ TestTable file:///data/hadoop/hbase-exported/TestTable
后来发现这种方式不好,导出的parted文件为分散在不同的datanode节点上。
(2)导出到HDFS中:
/home/hadoop/hbase/bin/hbase org.apache.hadoop.hbase.mapreduce.Driver export \ TestTable /hbase-exported/TestTable
3.将Hbase表导入到新的集群中
(1)首先将导出的文件copy到新集群的hdfs中
(2)创建Hbase表,指定了压缩格式为LZO
hbase(main):001:0> create 'TestTable',{NAME => 'r',COMPRESSION => 'LZO'}
0 row(s) in 0.7830 seconds
=> Hbase::Table - TestTable
hbase(main):002:0> list
TABLE
TestTable
1 row(s) in 0.0110 seconds
=> ["TestTable"]
hbase(main):003:0> describe 'TestTable'
Table TestTable is ENABLED
TestTable
COLUMN FAMILIES DESCRIPTION
{NAME => 'r', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOP
E => '0', VERSIONS => '1', COMPRESSION => 'LZO', MIN_VERSIONS => '0', TTL => 'FOREV
ER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLO
CKCACHE => 'true'}
1 row(s) in 0.0100 seconds
hbase(main):004:0>
(3)import数据:
/usr/local/hbase/bin/hbase -Dhbase.import.version=0.94 \ org.apache.hadoop.hbase.mapreduce.Import TestTable /hbase-exported/TestTable
说明:跨版本的import要指定版本号,-Dhbase.import.version=0.94
命令执行后会触发一个Mapreduce,不过很快任务就失败了,失败原因是:RegionTooBusyException。
分析了一下,由于hbase的key比较集中,import的时候全部落在了一个regionserver上,大量的并发写和split操作导致region不可用,最后任务失败。
想到的解决办法是:
预分配分区(pre-sharding),这需要根据key的实际情况进行分析处理
另外是尝试进行hbase的参数调优,而这次调优的目的是要让import/MR操作不失败,尽量的产生少的Map,同时减少触发split的机会。
经过多次调整参数,最后import成功完成,没再出现 RegionTooBusyException 错误。
主要涉及的参数如下:
1.调整了Region的大小,从之前的256M改成了2G
edit hbase-site.xml
<property>
<name>hbase.hregion.max.filesize</name>
<value>21474836480</value>
<description>这里region设置的大小为2GB.</description>
</property>
等迁移完成之后可以改成正常的大小,比如256M。
2.调整了MAP的个数
edit yarn-site.xml
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
<discription>每个节点可用内存,内存尽量减少,即使服务器有128G以上内存,这里指定最大可用20G</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>8192</value>
<discription>单个任务可申请最少内存,默认1024MB,这里指定8G</discription>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
<discription>单个任务可申请最大内存,默认8192MB,这里指定16G</discription>
</property>
通过以上调整,每个nodemanager最多能产生2个map,这样减少MAP的数量从而降低了对regionserver的压力。
具体导入过程:
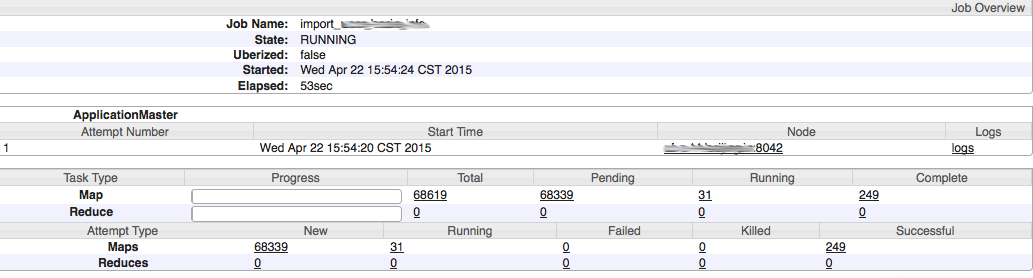
$/usr/local/hbase/bin/hbase -Dhbase.import.version=0.94 \ org.apache.hadoop.hbase.mapreduce.Import TestTable /hbase-exported/TestTable 2015-04-22 13:57:19,725 INFO [main] client.RMProxy: Connecting to ResourceManager at hadoopnn.sudops.com/172.18.3.100:8032 2015-04-22 13:57:21,517 INFO [main] input.FileInputFormat: Total input paths to process : 86 2015-04-22 13:57:21,767 INFO [main] mapreduce.JobSubmitter: number of splits:16886 2015-04-22 13:57:21,877 INFO [main] mapreduce.JobSubmitter: Submitting tokens for job: job_1429682175236_0001 2015-04-22 13:57:22,139 INFO [main] impl.YarnClientImpl: Submitted application application_1429682175236_0001 2015-04-22 13:57:22,172 INFO [main] mapreduce.Job: The url to track the job: http://hadoopnn.sudops.com:8088/proxy/application_1429682175236_0001/ 2015-04-22 13:57:22,172 INFO [main] mapreduce.Job: Running job: job_1429682175236_0001 2015-04-22 13:57:31,544 INFO [main] mapreduce.Job: Job job_1429682175236_0001 running in uber mode : false 2015-04-22 13:57:31,545 INFO [main] mapreduce.Job: map 0% reduce 0% 2015-04-22 13:57:56,585 INFO [main] mapreduce.Job: map 1% reduce 0% ... ... 2015-04-22 14:49:50,462 INFO [main] mapreduce.Job: map 99% reduce 0% 2015-04-22 14:50:36,070 INFO [main] mapreduce.Job: map 100% reduce 0% 2015-04-22 14:51:12,561 INFO [main] mapreduce.Job: Job job_1429682175236_0001 completed successfully 2015-04-22 14:51:12,636 INFO [main] mapreduce.Job: Counters: 32 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=2162795525 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=70710397627 HDFS: Number of bytes written=0 HDFS: Number of read operations=50652 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Failed map tasks=2 Launched map tasks=16886 Data-local map tasks=16877 Rack-local map tasks=9 Total time spent by all maps in occupied slots (ms)=92462095 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=92462095 Total vcore-seconds taken by all map tasks=92462095 Total megabyte-seconds taken by all map tasks=189362370560 Map-Reduce Framework Map input records=289975527 Map output records=289975527 Input split bytes=2228688 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=705085 CPU time spent (ms)=109627440 Physical memory (bytes) snapshot=6862689853440 Virtual memory (bytes) snapshot=30813109706752 Total committed heap usage (bytes)=17054170611712 File Input Format Counters Bytes Read=70708168939 File Output Format Counters Bytes Written=0
其实表也不是很大,才60G左右,后续导入过300G的表也没有问题!